Reproducible Builds: Reproducible Builds in July 2022
 Welcome to the July 2022 report from the Reproducible Builds project!
In our reports we attempt to outline the most relevant things that have been going on in the past month. As a brief introduction, the reproducible builds effort is concerned with ensuring no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Welcome to the July 2022 report from the Reproducible Builds project!
In our reports we attempt to outline the most relevant things that have been going on in the past month. As a brief introduction, the reproducible builds effort is concerned with ensuring no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Reproducible Builds summit 2022
Despite several delays, we are pleased to announce that registration is open for our in-person summit this year:
November 1st November 3rd
The event will happen in Venice (Italy). We intend to pick a venue reachable via the train station and an international airport. However, the precise venue will depend on the number of attendees.
Please see the announcement email for information about how to register.
Is reproducibility practical?
 Ludovic Court s published an informative blog post this month asking the important question: Is reproducibility practical?:
Ludovic Court s published an informative blog post this month asking the important question: Is reproducibility practical?:
Our attention was recently caught by a nice slide deck on the methods and tools for reproducible research in the R programming language. Among those, the talk mentions Guix, stating that it is for professional, sensitive applications that require ultimate reproducibility , which is probably a bit overkill for Reproducible Research . While we were flattered to see Guix suggested as good tool for reproducibility, the very notion that there s a kind of reproducibility that is ultimate and, essentially, impractical, is something that left us wondering: What kind of reproducibility do scientists need, if not the ultimate kind? Is reproducibility practical at all, or is it more of a horizon?
The post goes on to outlines the concept of reproducibility, situating examples within the context of the GNU Guix operating system.
diffoscope
 diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions
diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 218, 219 and 220 to Debian, as well as made the following changes:
-
New features:
- Support Haskell 9.x series files. [ ]
-
Bug fixes:
-
Output improvements:
- Improve output of Markdown and reStructuredText to use code blocks with highlighting. [ ]
-
Codebase improvements:
Mailing list
On our mailing list this month:
-
Roland Clobus posted his Eleventh status update about reproducible [Debian] live-build ISO images, noting amongst many other things! that all major desktops build reproducibly with bullseye, bookworm and sid.
-
Santiago Torres-Arias announced a Call for Papers (CfP) for a new SCORED conference, an academic workshop around software supply chain security . As Santiago highlights, this new conference invites reviewers from industry, open source, governement and academia to review the papers [and] I think that this is super important to tackle the supply chain security task .
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, however, we submitted the following patches:
-
Bernhard M. Wiedemann
- openSUSE monthly report
acarsdec (embeds CPU info with march=native)casacore (embeds CPU info with march=native)kubernetes (uses random name of temporary directory)setuptools/python-brotlicffi (toolchain, filesys/readdir)sysstat (FTBFS in single CPU mode)sundials (FTBFS in single CPU mode)nim (FTBFS in single CPU mode)doxygen/libzypp (toolchain readdir)python-pyquil (build failure)openssl-1_0_0 (build failure)jsonrpc-glib (FTBFS in single CPU mode)slurm (Link-Time Optimisation and .tar issues)wasi-libc (sort the output from find)
-
Chris Lamb:
-
Philip Rinn:
-
Vagrant Cascadian:
Reprotest
reprotest is the Reproducible Builds project s end-user tool to build the same source code twice in widely and deliberate different environments, and checking whether the binaries produced by the builds have any differences. This month, the following changes were made:
-
Holger Levsen:
-
Mattia Rizzolo:
Reproducible builds website
A number of changes were made to the Reproducible Builds website and documentation this month, including:
-
Arnout Engelen:
- Add a link to recent May Contain Hackers 2022 conference talk slides. [ ]
-
Chris Lamb:
-
Holger Levsen:
- Add talk from FOSDEM 2015 presented by Holger and Lunar. [ ]
- Show date of presentations if we have them. [ ][ ]
- Add my presentation from DebConf22 [ ] and from Debian Reunion Hamburg 2022 [ ].
- Add dhole to the speakers of the DebConf15 talk. [ ]
- Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. [ ]
- Drop some Debian-related suggested ideas which are not really relevant anymore. [ ]
- Add a link to list of packages with patches ready to be NMUed. [ ]
-
Mattia Rizzolo:
Testing framework
 The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
-
Debian-related changes:
- Create graphs displaying existing
.buildinfo files per each Debian suite/arch. [ ][ ]
- Fix a typo in the Debian dashboard. [ ][ ]
- Fix some issues in the
pkg-r package set definition. [ ][ ][ ]
- Improve the builtin-pho HTML output. [ ][ ][ ][ ]
- Temporarily disable all live builds as our snapshot mirror is offline. [ ]
-
Automated node health checks:
-
Misc changes:
- Test that FreeBSD virtual machine has been updated to version 13.1. [ ]
- Add a reminder about powercycling the
armhf-architecture mst0X node. [ ]
- Fix a number of typos. [ ][ ]
- Update documentation. [ ][ ]
- Fix Munin monitoring configuration for some nodes. [ ]
- Fix the static IP address for a node. [ ]
In addition, Vagrant Cascadian updated host keys for the cbxi4pro0 and wbq0 nodes [ ] and, finally, node maintenance was also performed by Mattia Rizzolo [ ] and Holger Levsen [ ][ ][ ].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
Ludovic Court s published an informative blog post this month asking the important question: Is reproducibility practical?:
Our attention was recently caught by a nice slide deck on the methods and tools for reproducible research in the R programming language. Among those, the talk mentions Guix, stating that it is for professional, sensitive applications that require ultimate reproducibility , which is probably a bit overkill for Reproducible Research . While we were flattered to see Guix suggested as good tool for reproducibility, the very notion that there s a kind of reproducibility that is ultimate and, essentially, impractical, is something that left us wondering: What kind of reproducibility do scientists need, if not the ultimate kind? Is reproducibility practical at all, or is it more of a horizon?The post goes on to outlines the concept of reproducibility, situating examples within the context of the GNU Guix operating system.
diffoscope
diffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 218, 219 and 220 to Debian, as well as made the following changes:
-
New features:
- Support Haskell 9.x series files. [ ]
-
Bug fixes:
-
Output improvements:
- Improve output of Markdown and reStructuredText to use code blocks with highlighting. [ ]
-
Codebase improvements:
Mailing list
On our mailing list this month:
-
Roland Clobus posted his Eleventh status update about reproducible [Debian] live-build ISO images, noting amongst many other things! that all major desktops build reproducibly with bullseye, bookworm and sid.
-
Santiago Torres-Arias announced a Call for Papers (CfP) for a new SCORED conference, an academic workshop around software supply chain security . As Santiago highlights, this new conference invites reviewers from industry, open source, governement and academia to review the papers [and] I think that this is super important to tackle the supply chain security task .
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, however, we submitted the following patches:
-
Bernhard M. Wiedemann
- openSUSE monthly report
acarsdec (embeds CPU info with march=native)casacore (embeds CPU info with march=native)kubernetes (uses random name of temporary directory)setuptools/python-brotlicffi (toolchain, filesys/readdir)sysstat (FTBFS in single CPU mode)sundials (FTBFS in single CPU mode)nim (FTBFS in single CPU mode)doxygen/libzypp (toolchain readdir)python-pyquil (build failure)openssl-1_0_0 (build failure)jsonrpc-glib (FTBFS in single CPU mode)slurm (Link-Time Optimisation and .tar issues)wasi-libc (sort the output from find)
-
Chris Lamb:
-
Philip Rinn:
-
Vagrant Cascadian:
Reprotest
reprotest is the Reproducible Builds project s end-user tool to build the same source code twice in widely and deliberate different environments, and checking whether the binaries produced by the builds have any differences. This month, the following changes were made:
-
Holger Levsen:
-
Mattia Rizzolo:
Reproducible builds website
A number of changes were made to the Reproducible Builds website and documentation this month, including:
-
Arnout Engelen:
- Add a link to recent May Contain Hackers 2022 conference talk slides. [ ]
-
Chris Lamb:
-
Holger Levsen:
- Add talk from FOSDEM 2015 presented by Holger and Lunar. [ ]
- Show date of presentations if we have them. [ ][ ]
- Add my presentation from DebConf22 [ ] and from Debian Reunion Hamburg 2022 [ ].
- Add dhole to the speakers of the DebConf15 talk. [ ]
- Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. [ ]
- Drop some Debian-related suggested ideas which are not really relevant anymore. [ ]
- Add a link to list of packages with patches ready to be NMUed. [ ]
-
Mattia Rizzolo:
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
-
Debian-related changes:
- Create graphs displaying existing
.buildinfo files per each Debian suite/arch. [ ][ ]
- Fix a typo in the Debian dashboard. [ ][ ]
- Fix some issues in the
pkg-r package set definition. [ ][ ][ ]
- Improve the builtin-pho HTML output. [ ][ ][ ][ ]
- Temporarily disable all live builds as our snapshot mirror is offline. [ ]
-
Automated node health checks:
-
Misc changes:
- Test that FreeBSD virtual machine has been updated to version 13.1. [ ]
- Add a reminder about powercycling the
armhf-architecture mst0X node. [ ]
- Fix a number of typos. [ ][ ]
- Update documentation. [ ][ ]
- Fix Munin monitoring configuration for some nodes. [ ]
- Fix the static IP address for a node. [ ]
In addition, Vagrant Cascadian updated host keys for the cbxi4pro0 and wbq0 nodes [ ] and, finally, node maintenance was also performed by Mattia Rizzolo [ ] and Holger Levsen [ ][ ][ ].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
- Support Haskell 9.x series files. [ ]
- Improve output of Markdown and reStructuredText to use code blocks with highlighting. [ ]
- Roland Clobus posted his Eleventh status update about reproducible [Debian] live-build ISO images, noting amongst many other things! that all major desktops build reproducibly with bullseye, bookworm and sid.
- Santiago Torres-Arias announced a Call for Papers (CfP) for a new SCORED conference, an academic workshop around software supply chain security . As Santiago highlights, this new conference invites reviewers from industry, open source, governement and academia to review the papers [and] I think that this is super important to tackle the supply chain security task .
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. This month, however, we submitted the following patches:
-
Bernhard M. Wiedemann
- openSUSE monthly report
acarsdec (embeds CPU info with march=native)casacore (embeds CPU info with march=native)kubernetes (uses random name of temporary directory)setuptools/python-brotlicffi (toolchain, filesys/readdir)sysstat (FTBFS in single CPU mode)sundials (FTBFS in single CPU mode)nim (FTBFS in single CPU mode)doxygen/libzypp (toolchain readdir)python-pyquil (build failure)openssl-1_0_0 (build failure)jsonrpc-glib (FTBFS in single CPU mode)slurm (Link-Time Optimisation and .tar issues)wasi-libc (sort the output from find)
-
Chris Lamb:
-
Philip Rinn:
-
Vagrant Cascadian:
Reprotest
reprotest is the Reproducible Builds project s end-user tool to build the same source code twice in widely and deliberate different environments, and checking whether the binaries produced by the builds have any differences. This month, the following changes were made:
-
Holger Levsen:
-
Mattia Rizzolo:
Reproducible builds website
A number of changes were made to the Reproducible Builds website and documentation this month, including:
-
Arnout Engelen:
- Add a link to recent May Contain Hackers 2022 conference talk slides. [ ]
-
Chris Lamb:
-
Holger Levsen:
- Add talk from FOSDEM 2015 presented by Holger and Lunar. [ ]
- Show date of presentations if we have them. [ ][ ]
- Add my presentation from DebConf22 [ ] and from Debian Reunion Hamburg 2022 [ ].
- Add dhole to the speakers of the DebConf15 talk. [ ]
- Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. [ ]
- Drop some Debian-related suggested ideas which are not really relevant anymore. [ ]
- Add a link to list of packages with patches ready to be NMUed. [ ]
-
Mattia Rizzolo:
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
-
Debian-related changes:
- Create graphs displaying existing
.buildinfo files per each Debian suite/arch. [ ][ ]
- Fix a typo in the Debian dashboard. [ ][ ]
- Fix some issues in the
pkg-r package set definition. [ ][ ][ ]
- Improve the builtin-pho HTML output. [ ][ ][ ][ ]
- Temporarily disable all live builds as our snapshot mirror is offline. [ ]
-
Automated node health checks:
-
Misc changes:
- Test that FreeBSD virtual machine has been updated to version 13.1. [ ]
- Add a reminder about powercycling the
armhf-architecture mst0X node. [ ]
- Fix a number of typos. [ ][ ]
- Update documentation. [ ][ ]
- Fix Munin monitoring configuration for some nodes. [ ]
- Fix the static IP address for a node. [ ]
In addition, Vagrant Cascadian updated host keys for the cbxi4pro0 and wbq0 nodes [ ] and, finally, node maintenance was also performed by Mattia Rizzolo [ ] and Holger Levsen [ ][ ][ ].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
- openSUSE monthly report
acarsdec(embeds CPU info withmarch=native)casacore(embeds CPU info withmarch=native)kubernetes(uses random name of temporary directory)setuptools/python-brotlicffi(toolchain, filesys/readdir)sysstat(FTBFS in single CPU mode)sundials(FTBFS in single CPU mode)nim(FTBFS in single CPU mode)doxygen/libzypp(toolchain readdir)python-pyquil(build failure)openssl-1_0_0(build failure)jsonrpc-glib(FTBFS in single CPU mode)slurm(Link-Time Optimisation and.tarissues)wasi-libc(sort the output fromfind)
- Holger Levsen:
- Mattia Rizzolo:
Reproducible builds website
A number of changes were made to the Reproducible Builds website and documentation this month, including:
-
Arnout Engelen:
- Add a link to recent May Contain Hackers 2022 conference talk slides. [ ]
-
Chris Lamb:
-
Holger Levsen:
- Add talk from FOSDEM 2015 presented by Holger and Lunar. [ ]
- Show date of presentations if we have them. [ ][ ]
- Add my presentation from DebConf22 [ ] and from Debian Reunion Hamburg 2022 [ ].
- Add dhole to the speakers of the DebConf15 talk. [ ]
- Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. [ ]
- Drop some Debian-related suggested ideas which are not really relevant anymore. [ ]
- Add a link to list of packages with patches ready to be NMUed. [ ]
-
Mattia Rizzolo:
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
-
Debian-related changes:
- Create graphs displaying existing
.buildinfo files per each Debian suite/arch. [ ][ ]
- Fix a typo in the Debian dashboard. [ ][ ]
- Fix some issues in the
pkg-r package set definition. [ ][ ][ ]
- Improve the builtin-pho HTML output. [ ][ ][ ][ ]
- Temporarily disable all live builds as our snapshot mirror is offline. [ ]
-
Automated node health checks:
-
Misc changes:
- Test that FreeBSD virtual machine has been updated to version 13.1. [ ]
- Add a reminder about powercycling the
armhf-architecture mst0X node. [ ]
- Fix a number of typos. [ ][ ]
- Update documentation. [ ][ ]
- Fix Munin monitoring configuration for some nodes. [ ]
- Fix the static IP address for a node. [ ]
In addition, Vagrant Cascadian updated host keys for the cbxi4pro0 and wbq0 nodes [ ] and, finally, node maintenance was also performed by Mattia Rizzolo [ ] and Holger Levsen [ ][ ][ ].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
- Add a link to recent May Contain Hackers 2022 conference talk slides. [ ]
- Add talk from FOSDEM 2015 presented by Holger and Lunar. [ ]
- Show date of presentations if we have them. [ ][ ]
- Add my presentation from DebConf22 [ ] and from Debian Reunion Hamburg 2022 [ ].
- Add dhole to the speakers of the DebConf15 talk. [ ]
- Add raboof s talk Reproducible Builds for Trustworthy Binaries from May Contain Hackers. [ ]
- Drop some Debian-related suggested ideas which are not really relevant anymore. [ ]
- Add a link to list of packages with patches ready to be NMUed. [ ]
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, Holger Levsen made the following changes:
-
Debian-related changes:
- Create graphs displaying existing
.buildinfofiles per each Debian suite/arch. [ ][ ] - Fix a typo in the Debian dashboard. [ ][ ]
- Fix some issues in the
pkg-rpackage set definition. [ ][ ][ ] - Improve the builtin-pho HTML output. [ ][ ][ ][ ]
- Temporarily disable all live builds as our snapshot mirror is offline. [ ]
- Create graphs displaying existing
- Automated node health checks:
-
Misc changes:
- Test that FreeBSD virtual machine has been updated to version 13.1. [ ]
- Add a reminder about powercycling the
armhf-architecturemst0Xnode. [ ] - Fix a number of typos. [ ][ ]
- Update documentation. [ ][ ]
- Fix Munin monitoring configuration for some nodes. [ ]
- Fix the static IP address for a node. [ ]
cbxi4pro0 and wbq0 nodes [ ] and, finally, node maintenance was also performed by Mattia Rizzolo [ ] and Holger Levsen [ ][ ][ ].
Contact
As ever, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mailing list:
rb-general@lists.reproducible-builds.org
#reproducible-builds on irc.oftc.net.
rb-general@lists.reproducible-builds.org





 Train route from Bratislava to Brussels
Train route from Bratislava to Brussels Train route from Brussels to London
Train route from Brussels to London Change of trains in London
Change of trains in London Change of trains in Exeter
Change of trains in Exeter









 As many of you may be aware, I work with
As many of you may be aware, I work with  In 2017, I was attending FOSDEM when GNOME announced that I was to become the new Executive Director of the Foundation. Now, nearly 5 years later, I ve decided the timing is right for me to step back and for GNOME to start looking for its next leader. I ve been working closely with Rob and the rest of the board to ensure that there s an extended and smooth transition, and that GNOME can continue to go from strength to strength.
GNOME has changed a lot in the last 5 years, and a lot has happened in that time. As a Foundation, we ve gone from a small team of 3, to employing people to work on marketing, investment in technical frameworks, conference organisation and much more beyond. We ve become the default desktop on all major Linux distributions. We ve launched Flathub to help connect application developers directly to their users. We ve dealt with patent suits, trademarks, and bylaw changes. We ve moved our entire development platform to GitLab. We released 10 new GNOME releases, GTK 4 and GNOME 40. We ve reset our relationships with external community partners and forged our way towards that future we all dream of where everyone is empowered by technology they can trust.
For that future, we now need to build on that work. We need to look beyond the traditional role that desktop Linux has held and this is something that GNOME has always been able to do. I ve shown that the Foundation can be more than just a bank account for the project, and I believe that this is vital in our efforts to build a diverse and sustainable free software personal computing ecosystem. For this, we need to establish programs that align not only with the unique community and technology of the project, but also deliver those benefits to the wider world and drive real impact.
5 years has been the longest that the Foundation has had an ED for, and certainly the longest that I ve held a single post for. I remember my first GUADEC as ED. As you may know, like many of you, I m used to giving talks at conferences and yet I have never been so nervous as when I walked out on that stage. However, the welcome and genuine warmth that I received that day, and the continued support throughout the last 5 years makes me proud of what a welcoming and amazing community GNOME is. Thank you all.
In 2017, I was attending FOSDEM when GNOME announced that I was to become the new Executive Director of the Foundation. Now, nearly 5 years later, I ve decided the timing is right for me to step back and for GNOME to start looking for its next leader. I ve been working closely with Rob and the rest of the board to ensure that there s an extended and smooth transition, and that GNOME can continue to go from strength to strength.
GNOME has changed a lot in the last 5 years, and a lot has happened in that time. As a Foundation, we ve gone from a small team of 3, to employing people to work on marketing, investment in technical frameworks, conference organisation and much more beyond. We ve become the default desktop on all major Linux distributions. We ve launched Flathub to help connect application developers directly to their users. We ve dealt with patent suits, trademarks, and bylaw changes. We ve moved our entire development platform to GitLab. We released 10 new GNOME releases, GTK 4 and GNOME 40. We ve reset our relationships with external community partners and forged our way towards that future we all dream of where everyone is empowered by technology they can trust.
For that future, we now need to build on that work. We need to look beyond the traditional role that desktop Linux has held and this is something that GNOME has always been able to do. I ve shown that the Foundation can be more than just a bank account for the project, and I believe that this is vital in our efforts to build a diverse and sustainable free software personal computing ecosystem. For this, we need to establish programs that align not only with the unique community and technology of the project, but also deliver those benefits to the wider world and drive real impact.
5 years has been the longest that the Foundation has had an ED for, and certainly the longest that I ve held a single post for. I remember my first GUADEC as ED. As you may know, like many of you, I m used to giving talks at conferences and yet I have never been so nervous as when I walked out on that stage. However, the welcome and genuine warmth that I received that day, and the continued support throughout the last 5 years makes me proud of what a welcoming and amazing community GNOME is. Thank you all.

](https://jmtd.net/log/lightning/tweet.jpg)


 Now that UDP was working, I was able to get TCP to work using two PlutoSDRs,
which allowed me to run the cURL command I pasted in the first post (both
simultaneously listen and transmit on behalf of my TAP interface).
It s my hope that someone out there will be inspired to implement their own
Layer 1 and Layer 2 as a learning exercise, and gets the same sense of
gratification that I did! If you re reading this, and at a point
where you ve been able to send IP traffic over your own Layer 1 / Layer 2,
please get in touch! I d be thrilled to hear all about it. I d love to link
to any posts or examples you publish here!
Now that UDP was working, I was able to get TCP to work using two PlutoSDRs,
which allowed me to run the cURL command I pasted in the first post (both
simultaneously listen and transmit on behalf of my TAP interface).
It s my hope that someone out there will be inspired to implement their own
Layer 1 and Layer 2 as a learning exercise, and gets the same sense of
gratification that I did! If you re reading this, and at a point
where you ve been able to send IP traffic over your own Layer 1 / Layer 2,
please get in touch! I d be thrilled to hear all about it. I d love to link
to any posts or examples you publish here!
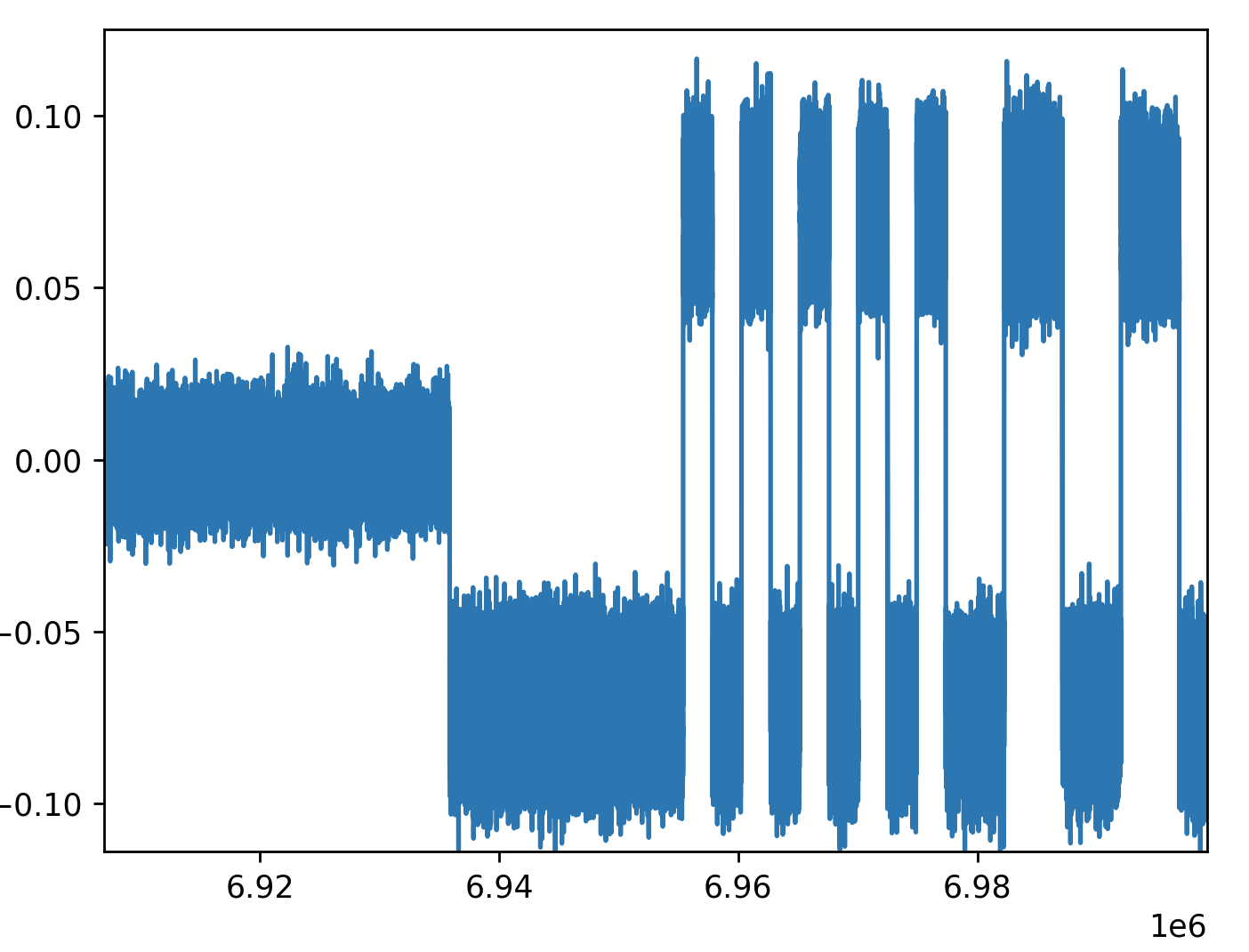
 I bought an HP 437B, which is the cutting edge of 30 years ago, but still
accurate to within 0.01dBm. I paired this Power Meter with an Agilent 8481A
Power Sensor (-30 dBm to 20 dBm from 10MHz to 18GHz). For some of my radios, I
was worried about exceeding the 20 dBm mark, so I used a 20db attenuator while
I waited for a higher power power sensor. Finally, I was able to find a GPIB to
USB interface, and get that interface working with the GPIB Kernel driver on my
system.
With all that out of the way, I was able to write
I bought an HP 437B, which is the cutting edge of 30 years ago, but still
accurate to within 0.01dBm. I paired this Power Meter with an Agilent 8481A
Power Sensor (-30 dBm to 20 dBm from 10MHz to 18GHz). For some of my radios, I
was worried about exceeding the 20 dBm mark, so I used a 20db attenuator while
I waited for a higher power power sensor. Finally, I was able to find a GPIB to
USB interface, and get that interface working with the GPIB Kernel driver on my
system.
With all that out of the way, I was able to write 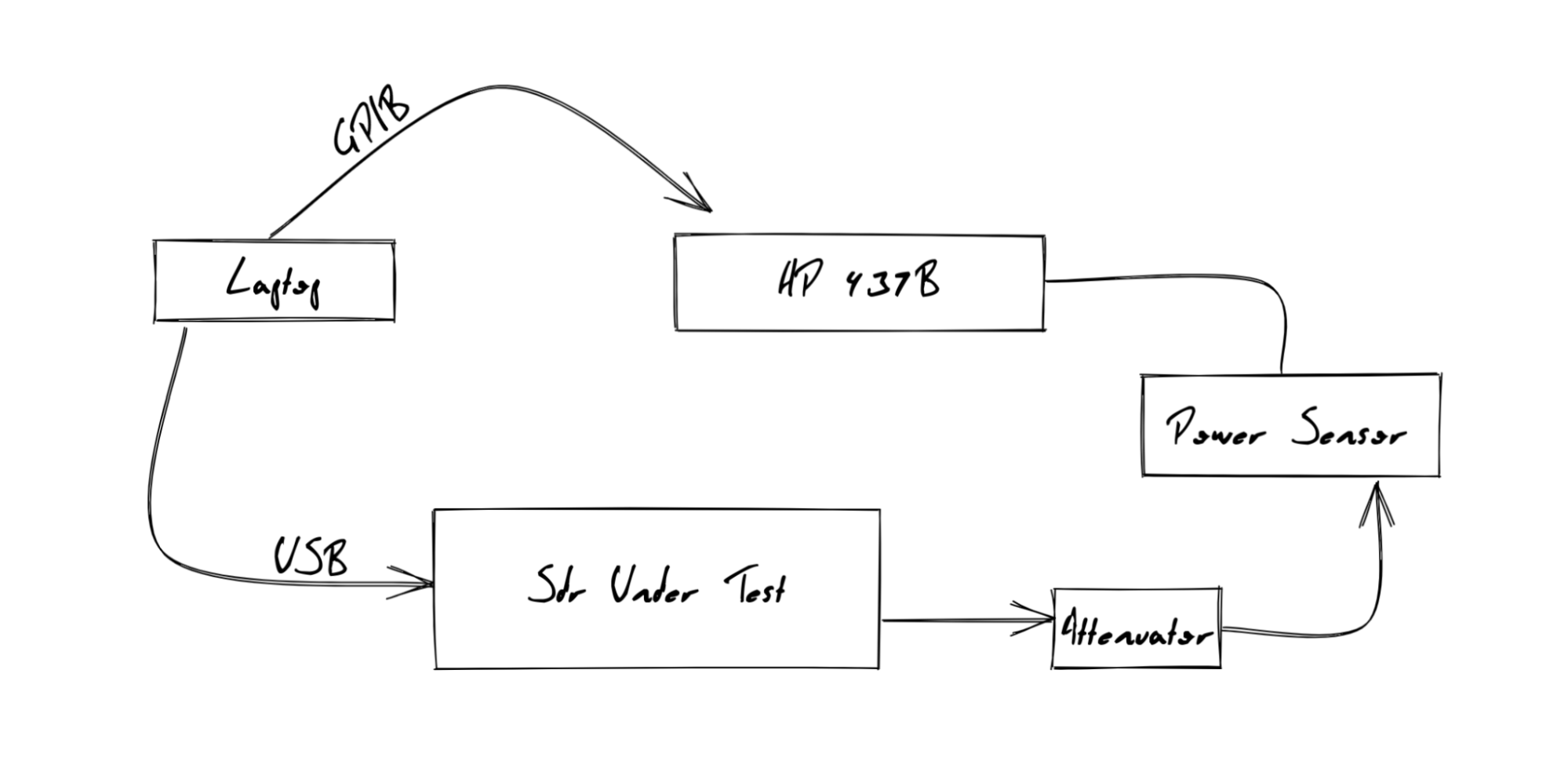
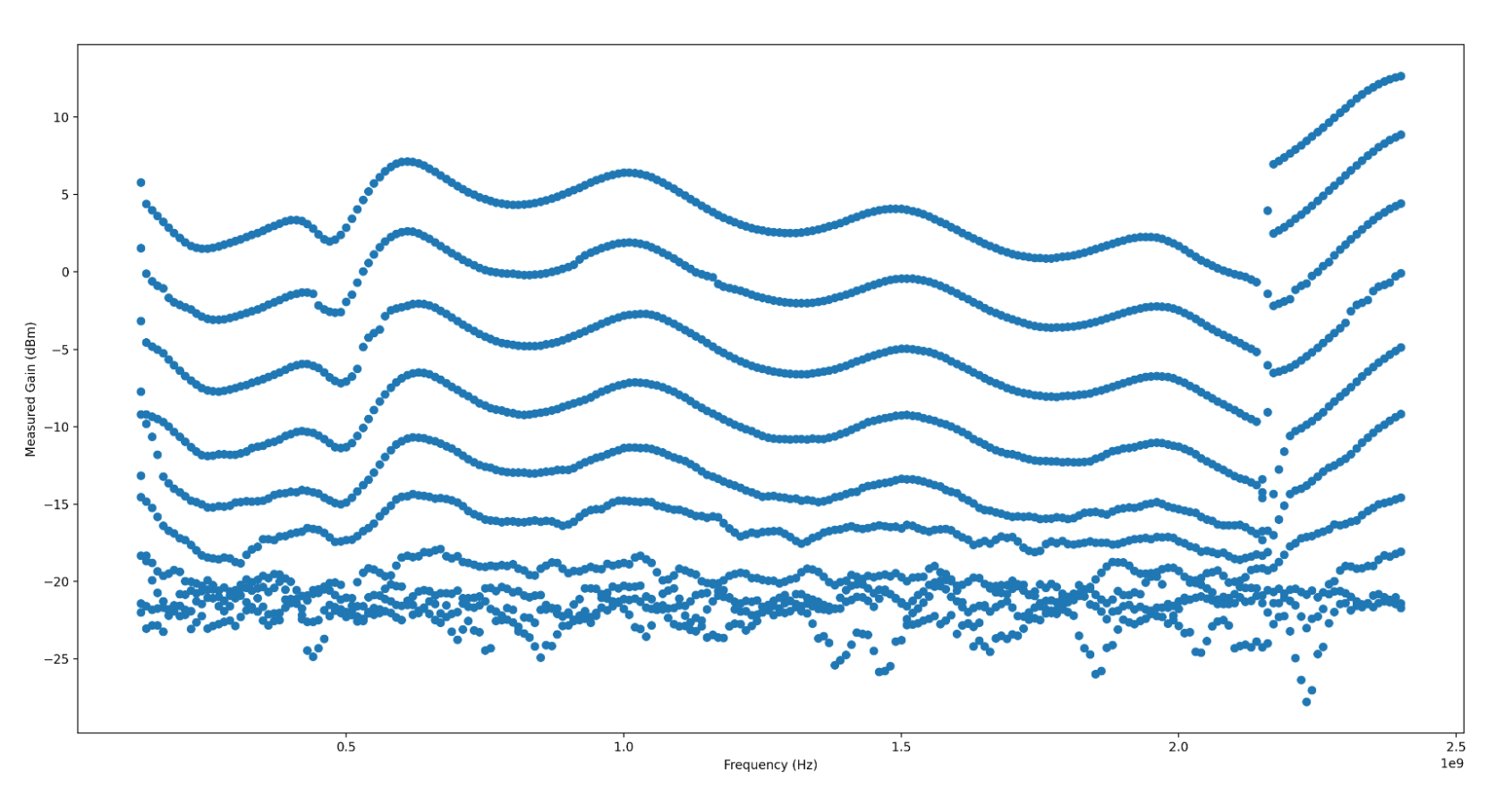
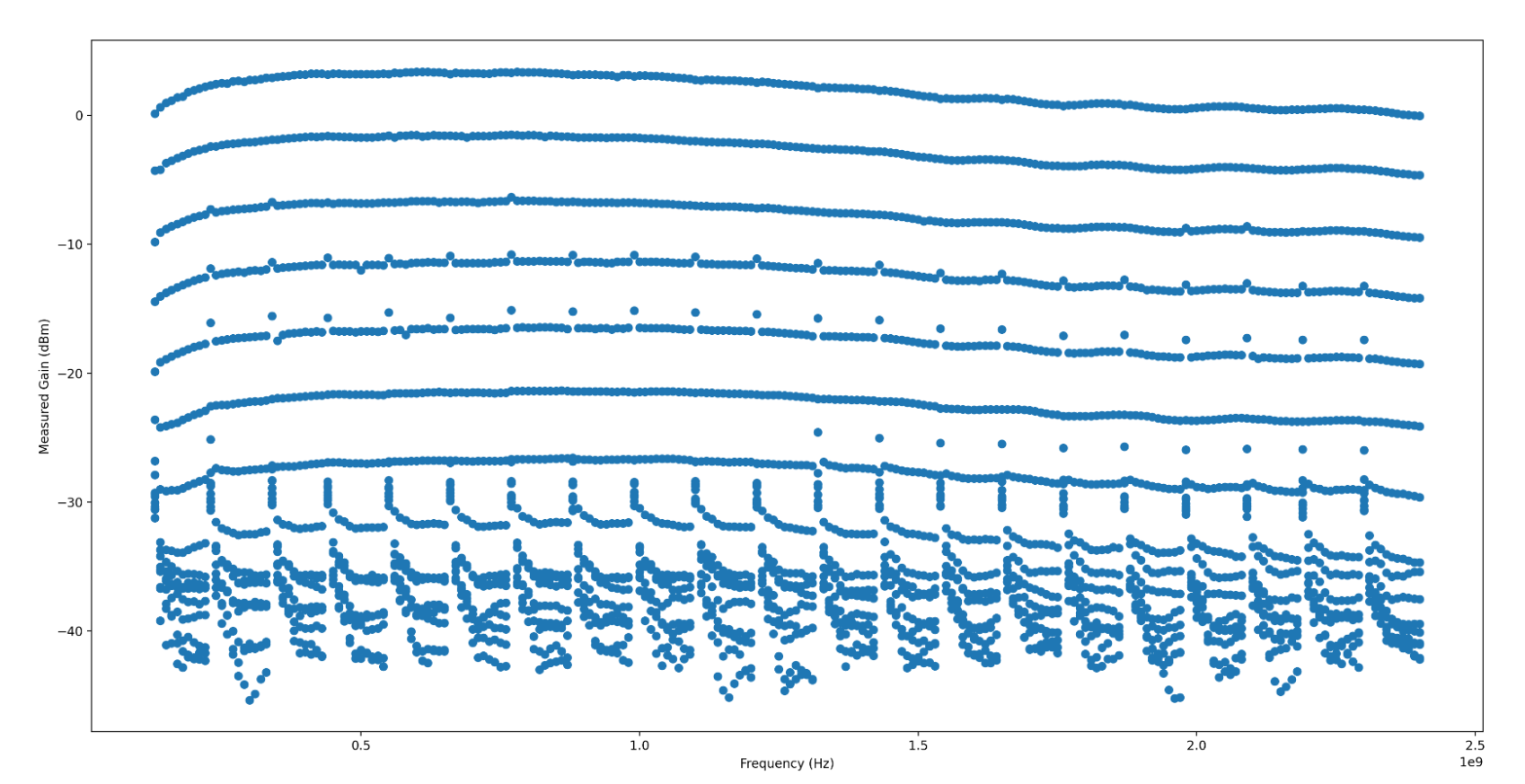
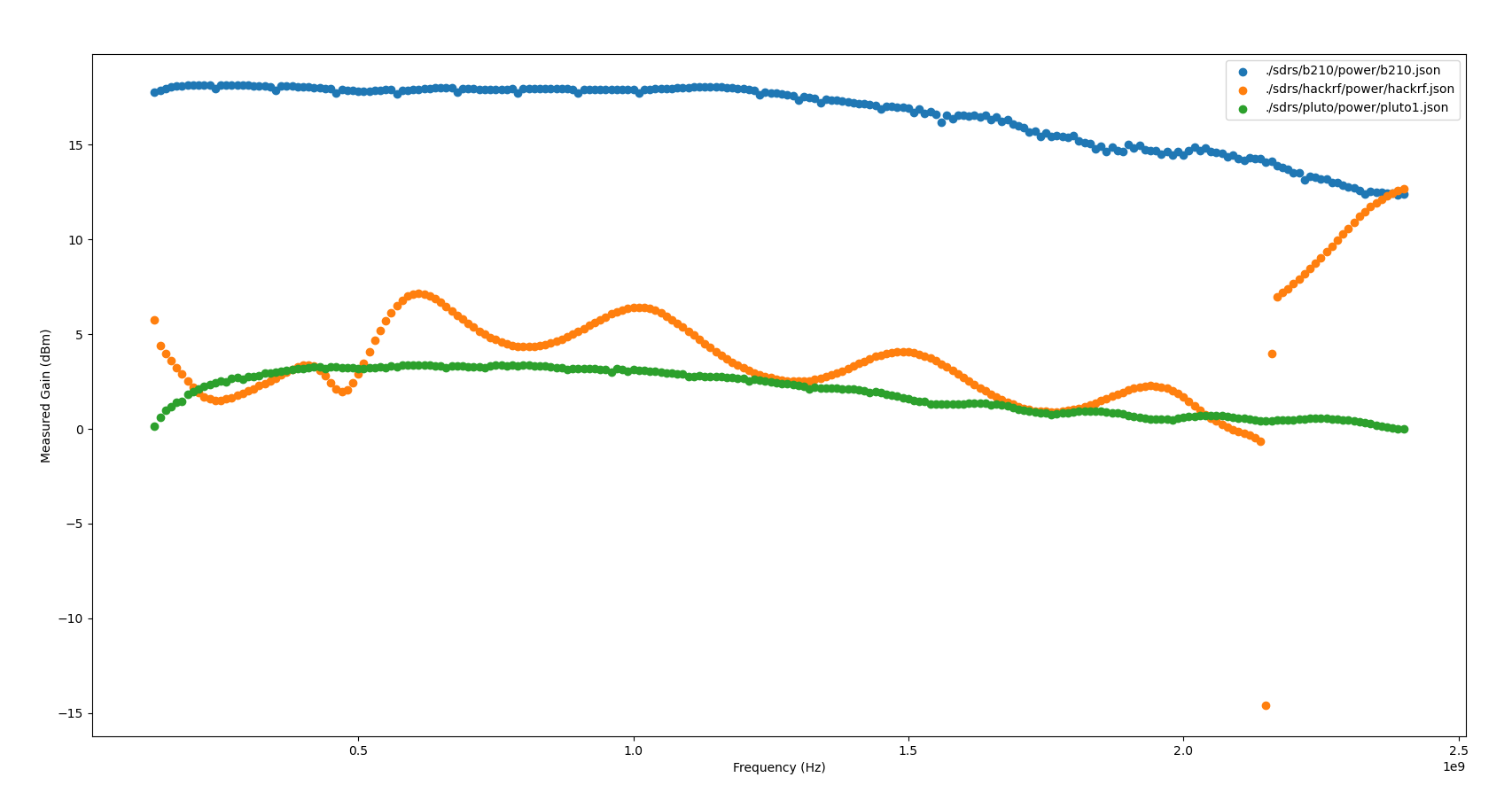
 When looking at output power over the frequency range swept, the HackRF
contains a distinctive (and frankly jarring) ripple across the Frequency range,
with a clearly visible jump in gain somewhere around 2.1GHz. I have no idea
what is causing this massive jump in output gain, nor what is causing these
distinctive ripples. I d love to know more if anyone s familiar with HackRF s
RF internals!
When looking at output power over the frequency range swept, the HackRF
contains a distinctive (and frankly jarring) ripple across the Frequency range,
with a clearly visible jump in gain somewhere around 2.1GHz. I have no idea
what is causing this massive jump in output gain, nor what is causing these
distinctive ripples. I d love to know more if anyone s familiar with HackRF s
RF internals!
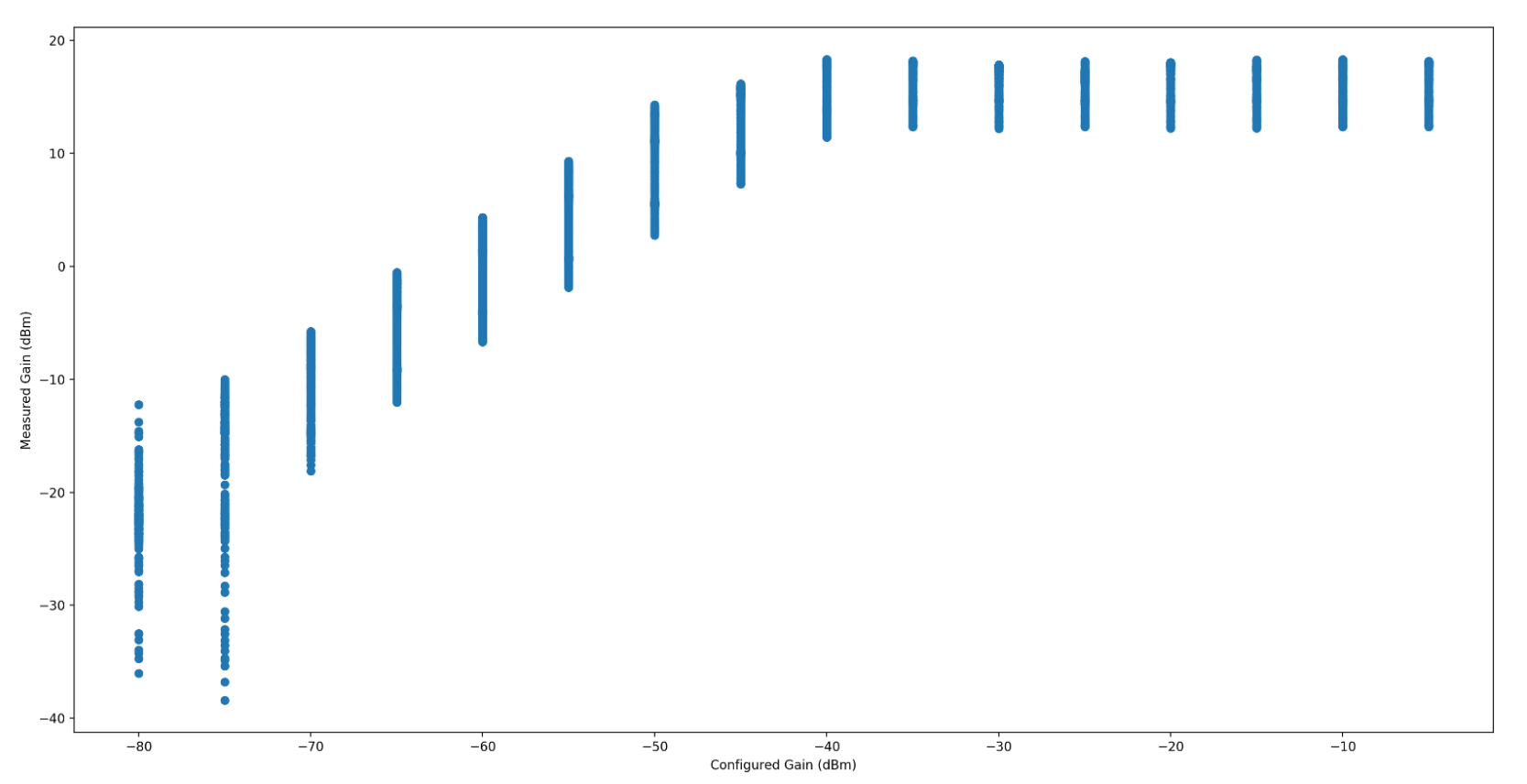
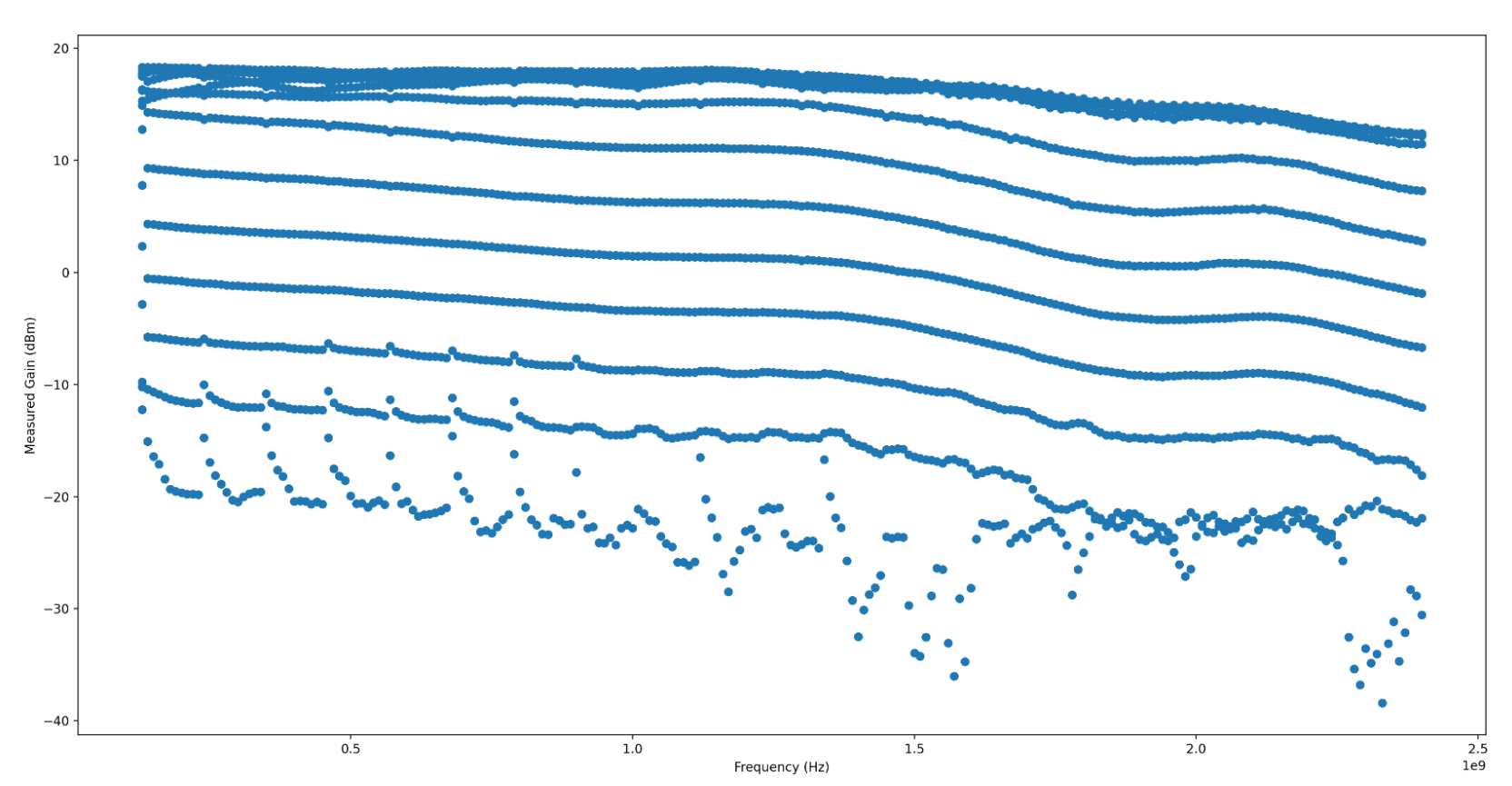
 Generally, the power output is quite stable, and looks to have very even and
wideband gain control. There s a few artifacts, which I have not confidently
isolated to the SDR TX gain, noise (transmit artifacts such as intermodulation)
or to my test setup. They appear fairly narrowband, so I m not overly worried
about them yet. If anyone has any ideas what this could be, I d very much
appreciate understanding why they exist!
Generally, the power output is quite stable, and looks to have very even and
wideband gain control. There s a few artifacts, which I have not confidently
isolated to the SDR TX gain, noise (transmit artifacts such as intermodulation)
or to my test setup. They appear fairly narrowband, so I m not overly worried
about them yet. If anyone has any ideas what this could be, I d very much
appreciate understanding why they exist!
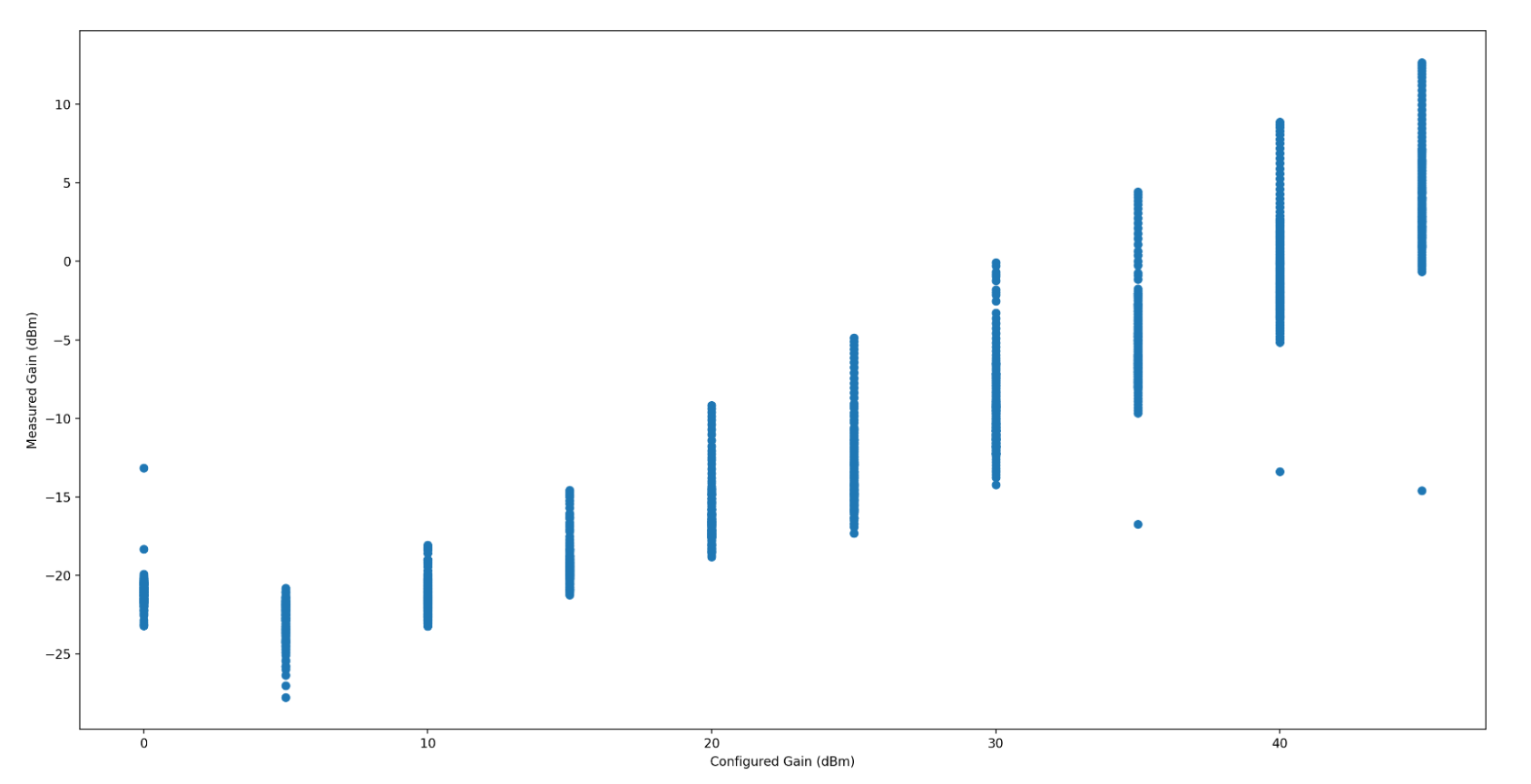
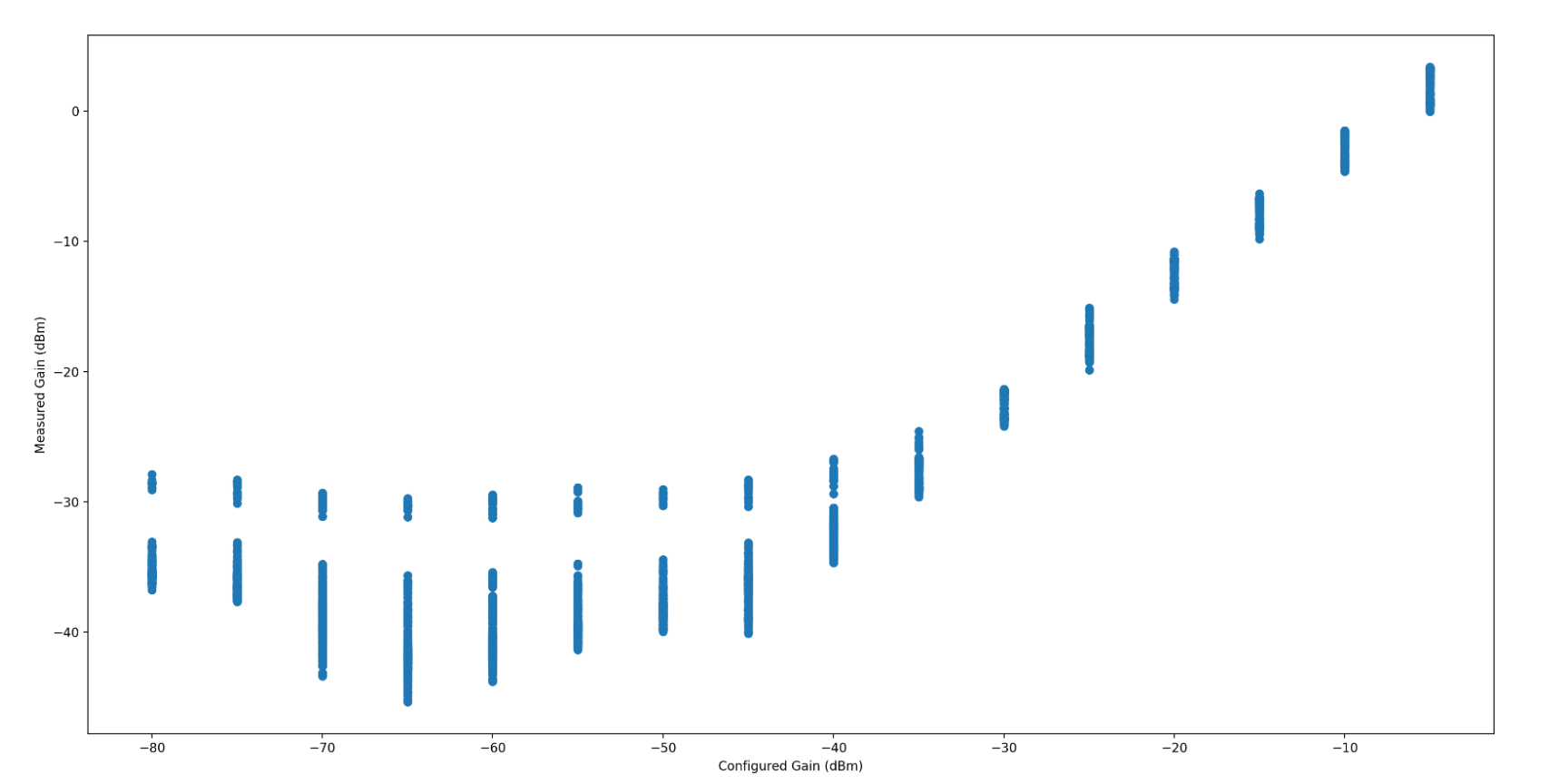
 When the Gain is somewhere around the noise floor, the measured gain is
incredibly erratic, which throws the maximum standard deviation significantly.
I haven t isolated that to my test setup or the radio itself. I m inclined to
believe it s my test setup. The radio has a fairly even and wideband gain, and
so long as you re operating between -70dB to -55dB, fairly linear as well.
When the Gain is somewhere around the noise floor, the measured gain is
incredibly erratic, which throws the maximum standard deviation significantly.
I haven t isolated that to my test setup or the radio itself. I m inclined to
believe it s my test setup. The radio has a fairly even and wideband gain, and
so long as you re operating between -70dB to -55dB, fairly linear as well.








 The Python programming language is one of the most popular and in huge demand. It is free, has a large community, is intended for the development of projects of varying complexity, is easy to learn, and opens up great opportunities for programmers. To work comfortably with it, you need special Python tools, which are able to simplify your work. We have selected the best Python tools that will be relevant in 2021.
The Python programming language is one of the most popular and in huge demand. It is free, has a large community, is intended for the development of projects of varying complexity, is easy to learn, and opens up great opportunities for programmers. To work comfortably with it, you need special Python tools, which are able to simplify your work. We have selected the best Python tools that will be relevant in 2021.





 Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Recent Uploads to Debian related to Lomiri (Feb - May 2021)
Over the past 4 months I attended 14 of the weekly scheduled UBports development sync sessions and worked on the following bits and pieces regarding Lomiri in Debian:
Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Recent Uploads to Debian related to Lomiri (Feb - May 2021)
Over the past 4 months I attended 14 of the weekly scheduled UBports development sync sessions and worked on the following bits and pieces regarding Lomiri in Debian: